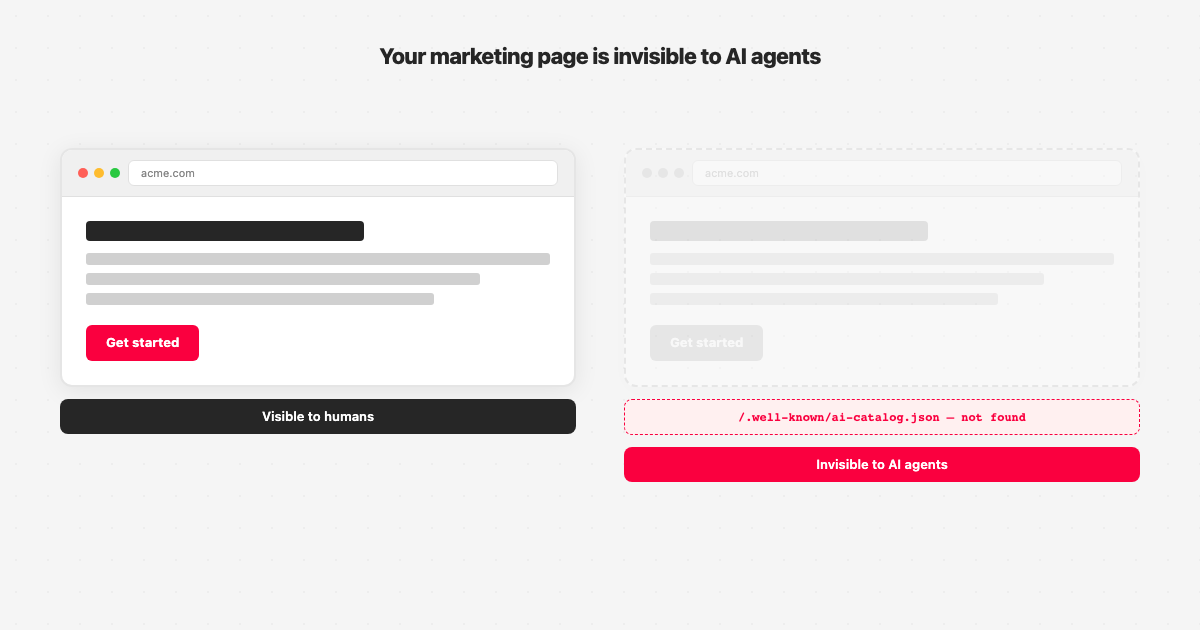
Your Marketing Page Is Invisible to AI Agents. Here Is the Open Spec Trying to Change That.
On June 17, 2026, eleven tech companies published an open spec for how AI agents discover resources on the web. The mechanism isn't a keyword or a backlink. It's a list of example questions. Here's what the spec says and how to audit your page against it.
On June 17, 2026, Google, Microsoft, NVIDIA, Salesforce, Hugging Face, Cisco, Databricks, GoDaddy, GitHub, ServiceNow, and Snowflake jointly published an open specification for how AI agents discover resources on the web.[1][4] Eleven founding partners, one draft spec. The thing that makes a resource discoverable under it isn't a keyword or a backlink. It's a list of example natural-language questions a user might ask an agent.
If your marketing page doesn't have one of those, an AI agent following this spec has no mechanism to find it. Right now, almost no marketing page does.
The spec is called Agentic Resource Discovery (ARD). It's a real draft, v0.9, published under Apache 2.0, built under the Linux Foundation's AI Catalog Working Group, and it's aimed primarily at AI tools, MCP servers, and API capabilities, not marketing landing pages.[1] The honest framing: if you publish marketing content rather than developer tools, ARD doesn't require immediate action. But the pattern it establishes (that machine-readable discoverability metadata belongs at a well-known URL on every domain that wants to be found) is the same pattern SEO and GEO established before it. That trajectory is worth understanding before it becomes a catch-up exercise.
This piece explains what ARD is, what ai-catalog.json contains, why one field in particular is the concept to pay attention to, and what you can check on your own domain today.
From Keywords to Conversations to Agents: How the Discovery Stack Evolved
Search discovery has always been a negotiation between publishers and the systems that route traffic to them. The terms of that negotiation have shifted three times in a decade, and each shift happened because the underlying search behavior changed first.
SEO was built around keywords and crawlers. A page that wanted to be found for a query needed the query's terms on the page, structured in a way a search-engine bot could parse and index. The whole discipline (title tags, heading hierarchy, alt text, internal linking) was designed to speak to a bot that read text and counted signals.
GEO (generative engine optimization) entered when large language models started generating direct answers instead of link lists. Ranking wasn't enough anymore. If the model summarized a topic without citing your page, you were invisible to any user who stopped at the answer. The response: write for inclusion in generated summaries. Be cited. Be specific enough that a model's summarizer reaches for your language.
AEO (answer engine optimization) extended that further. Not just "write to be included" but "structure content so a model can extract and re-present it accurately." The shift was from optimizing for indexing to optimizing for quotation.
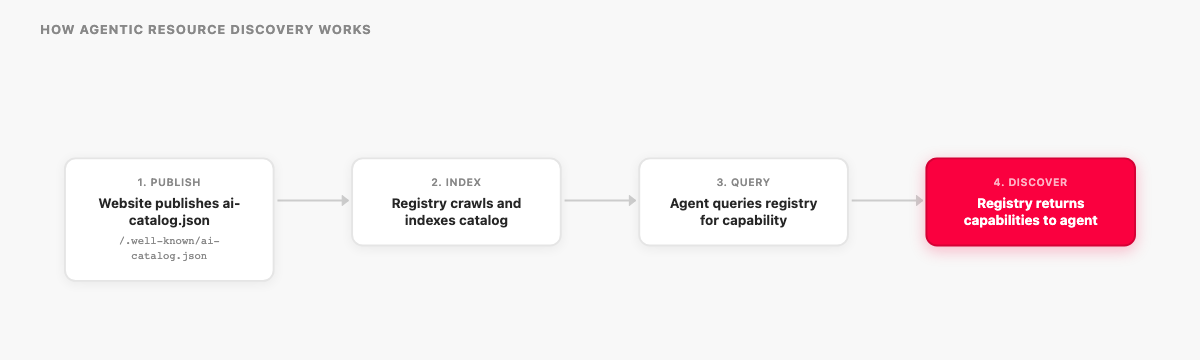
Agent discovery is different in kind, not just in degree. The shift here isn't in how content is indexed. It's in who does the searching. Autonomous agents don't run queries through a general-purpose search engine and then decide what to do with the results. They look for published capability metadata at known locations on a domain and use that metadata to determine whether the domain has anything relevant to offer.[2] The mechanism is closer to how a developer reads an API's documentation than to how a user runs a search query.
ARD, published June 17, 2026, is an open specification for that fourth layer.[1] Calling it a "fourth layer" or "the discovery layer after AEO" is my framing, not the spec's language. The spec describes a technical mechanism for cataloging and indexing capabilities. The interpretation that it sits in sequence with SEO, GEO, and AEO is a way to place it in context for the audience of this post. If you're interested in where the conversation-first architecture sits in relation to this shift, the design argument for making conversation the publishing layer itself covers the structural question.
What Agentic Resource Discovery Is (and What the Spec Actually Targets)
The spec's core mechanism is a static manifest file called ai-catalog.json, hosted at a well-known path on any domain: /.well-known/ai-catalog.json.[1][3]
A domain that publishes this file is advertising its capabilities to any agent (or registry) that knows to look there. The catalog describes what the domain offers: MCP servers, A2A agents, OpenAPI tools, or nested catalogs pointing to other manifests. Registries crawl published catalogs, index their contents, and make them searchable, so when an agent needs a specific capability at runtime, it can query the registry rather than needing every tool pre-installed.[1][2] The agent gets back matching capabilities plus the verification metadata needed to trust the publisher.
That last point is deliberate design. Discovery and trust travel together in this spec. The catalog includes enough metadata for an agent to verify that the capability it found actually belongs to the domain that published it. That's different from how a web page works: a page can claim anything, and a user decides whether to trust it. A catalog entry is meant to be verifiable.
This is also where the scope caveat belongs. Eleven companies put their names behind this spec, including Google, Microsoft, Hugging Face, NVIDIA, and Salesforce.[4] That founding list is not provisional. What is provisional: Google's own Agent Registry, which would serve as a central index for published catalogs, is reportedly months away from production.[4] The ecosystem of registries that would crawl and index catalogs at scale is still early. Search Engine Journal reported that the spec "primarily affects companies that publish tools and agents" rather than typical content websites, and that adoption is in its earliest stages.[4] As of today, a marketing page is not the intended target. That's an honest framing, not a reason to skip the next section.
Understanding what agents do with published capabilities helps clarify what they're missing when a domain has none. The approval-gate decisions at WordPress and Webflow describe what agents do once they reach a site. This is about whether they find it.
The Field That Stands In for a Meta Description
If you've spent time on on-page SEO, you know what a meta description is: a short, author-supplied hint to search engines and users about what a page contains. It doesn't directly determine ranking, but it shapes whether a searcher clicks. It's you telling the discovery layer what the resource is for.
The ARD spec has an equivalent field. It's called representativeQueries.
representativeQueries is an optional field in the ai-catalog.json schema. The spec defines it as "sample natural-language queries" that registries use to build semantic vector embeddings for search ranking.[3] In plain language: you supply a list of things a user might ask an agent, and the registry uses those examples to determine what your catalog entry should match when agents come looking. The spec recommends 2 to 5 examples. Its own illustrative example is "find me a flight booking agent".[3]
The parallel to a meta description is the post's inference, not the spec's framing. But it's a useful one. Both fields solve the same underlying problem: the discovery layer can analyze your content on its own, but you can also give it a direct signal about what you're for. With meta descriptions, that signal was a sentence written for human readers and search engine snippets. With representativeQueries, it's a list of example questions written to seed a vector embedding that will be matched against agent queries at runtime.
For a marketer, this field is where the author's intent and the agent's retrieval mechanism meet directly. If registries eventually index marketing catalogs (a step that would require the spec to expand beyond its current tools/agents scope), the quality of those example queries would determine whether a catalog surfaces for relevant requests. That's not very different from choosing which query a page is optimized for. The question is just posed in natural language rather than in keyword syntax.

How to Audit Your Page for Agent Discoverability Today
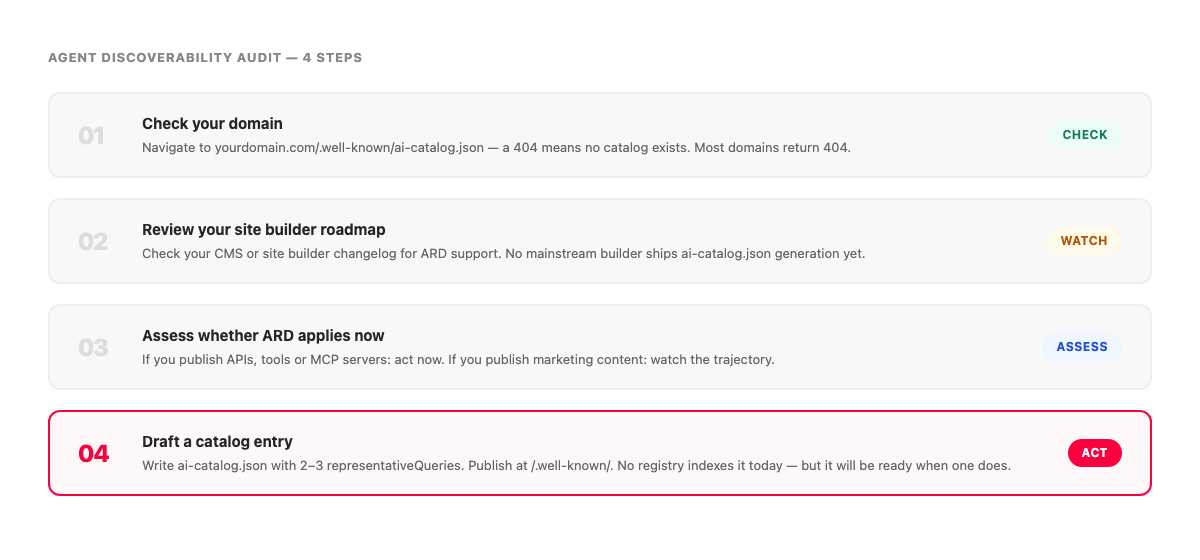
The audit below is four steps. It takes about ten minutes. The honest conclusion in advance: almost nobody passes step one, and that's the current baseline for the whole web, not a gap specific to your domain.
Step 1: Check whether your domain publishes /.well-known/ai-catalog.json.
Navigate to https://yourdomain.com/.well-known/ai-catalog.json in a browser. A 404 means no catalog exists. That's the current state for the vast majority of domains, including most that are actively working on GEO and AEO.[4] You're checking for awareness of where you are, not diagnosing a problem you've created.
Step 2: Check your site builder or CMS for ARD support.
The spec is less than a week old as of this writing. No mainstream site builder has shipped native ai-catalog.json generation as of this writing. Check the changelog and roadmap of your platform and watch for it. A publishing layer that already manages sitemap generation and page-route discovery is the natural place for a manifest like this to be generated automatically. That's a category-level observation about where the infrastructure fits, not a claim about any specific platform today.
Step 3: Assess whether ARD applies to you now or later. If you publish APIs, tools, MCP servers, or AI skills, ARD is directly relevant today. You're the intended audience for v0.9 and the infrastructure being built around it. If you publish marketing content for human readers, you're not the current target. The spec is a draft, the registries that would index marketing catalogs don't exist yet, and the scope hasn't expanded to content sites. Watch the trajectory rather than acting on urgency that isn't there.
Step 4: If you want to get ahead, draft a catalog entry.
The spec is Apache 2.0 and publicly available.[3] Read the schema, draft an ai-catalog.json describing your domain's purpose, and write two or three representativeQueries that capture what a user might ask an agent to find your resource. Publish the file at /.well-known/ai-catalog.json. No registry will index it today, but it will be there when one does, and you'll understand the format before it becomes an item on someone else's checklist.
The audit is worth running once now. Not because the urgency is high, but because understanding where you stand costs less than a surprise catch-up later. Once an agent does discover a page and sends someone to it, the design question becomes how that visitor behaves and what the page needs to do for them. AI-referred visitors navigate pages differently from cold-discovery traffic. That's the design side of the same problem.
ARD is v0.9. Draft status, Apache 2.0, under active development. The eleven founding companies behind it are not draft.
When Google, Microsoft, NVIDIA, and Salesforce agree on a discovery format, the trajectory tends to hold even when the timeline is uncertain. The SEO playbook didn't become mandatory the day Google's first algorithm launched. It became mandatory gradually, and the practitioners who understood it early had a structural advantage over the ones who caught up under pressure.
The question for a founder or marketer isn't "do I need to implement this today?" The answer to that question is probably no, unless you publish tools. The question worth asking is "do I understand what layer is forming beneath me?" This post was an answer to that one.
If it's useful, share it with your SEO or growth lead.
References
- Google Developers Blog, "Announcing the Agentic Resource Discovery specification" (published 2026-06-17). Describes ARD as "an open specification for publishing, discovering, and verifying AI capabilities across the web"; ai-catalog.json hosted at /.well-known/ai-catalog.json; catalog entries describe MCP servers, A2A agents, OpenAPI tools, and nested catalogs; registries "crawl published catalogs, index their contents, and make them searchable"; built under the Linux Foundation's AI Catalog Working Group. https://developers.googleblog.com/announcing-the-agentic-resource-discovery-specification/
- Hugging Face Blog, "Agentic Resource Discovery: Let agents search" (published 2026-06-17). Authors: Ben Burtenshaw and Shaun Smith (Hugging Face). ARD is "a draft, open specification" that "defines how agents and tools are cataloged, indexed, and searched across federated registries, so an agent can find capabilities at runtime instead of needing them pre-installed"; ai-catalog.json is "a static manifest format" at a well-known URL. Hugging Face is a co-author of the specification. https://huggingface.co/blog/agentic-resource-discovery-launch
- Agentic Resource Discovery, official specification, version 0.9 (Draft), dated 2026-05-28. Status: Proposal. License: Apache 2.0. Defines the representativeQueries field as "sample natural-language queries" that registries use "to build semantic vector embeddings for search ranking"; spec recommends 2-5 examples; illustrative example query: "find me a flight booking agent". Primary source for all spec mechanics and field definitions cited in this post. https://agenticresourcediscovery.org/spec/
- Search Engine Journal, "Google, Microsoft Back Draft AI Agent Discovery Spec" (published 2026-06-17). Source of the 11 founding partners list: Google, Microsoft, GitHub, Hugging Face, Cisco, Databricks, GoDaddy, NVIDIA, Salesforce, ServiceNow, Snowflake. Spec is Draft v0.9 under Apache 2.0. Google's Agent Registry support is "months out"; adoption is described as early and the spec "primarily affects companies that publish tools and agents." Adoption framing is the outlet's independent assessment, not a measured finding. https://www.searchenginejournal.com/google-microsoft-back-draft-ai-agent-discovery-spec/579894/